Le DOM, c'est quoi exactement ?
Le DOM (Document Object Model) est une interface pour vos pages web. C'est une API permettant aux programmes de lire et de manipuler le contenu de la page, sa structure et ses styles. Passons tout cela en revue pour comprendre comment ça marche.
Comment une page web est-elle construite ?
Le cheminement d'un navigateur partant d'un document source HTML pour finalement afficher une page stylée et interactive s'appelle le chemin critique du rendu (critical rendering path). Ce processus peut comporter de nombreuses étapes, comme je le montre dans mon article sur le sujet, mais celles-ci peuvent être regroupées en deux grandes étapes. La première consiste en l'analyse du document par le navigateur pour déterminer ce qui sera finalement rendu sur la page, et la seconde est le rendu par le navigateur.
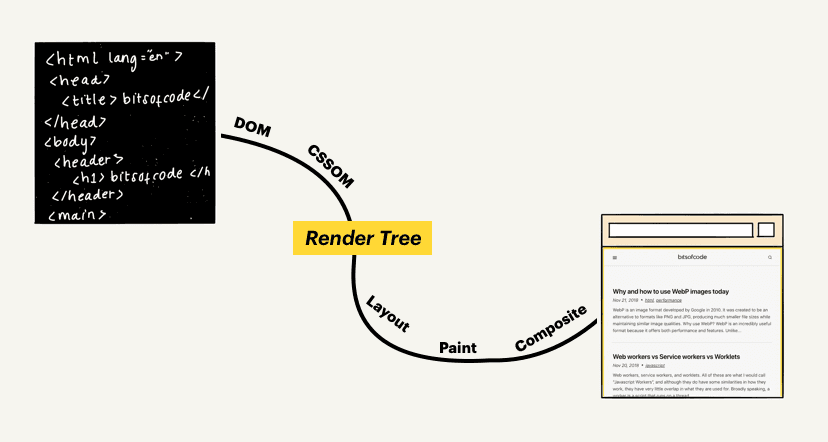
La première étape permet de construire l'arbre de rendu (render tree), une représentation sous forme d'arbre des éléments HTML qui seront rendus sur la page ainsi que leurs styles associés. Pour cela, le navigateur a besoin de deux choses :
- le CSSOM, une représentation des styles associés aux éléments
- le DOM, la représentation des éléments
Comment le DOM est créé, et à quoi il ressemble
Le DOM est une représentation du document HTML source. Comme nous le verrons plus loin, il comporte quelques différences, mais il s’agit pour l'essentiel d’une conversion de la structure et du contenu du document HTML en un modèle objet utilisable par divers programmes.
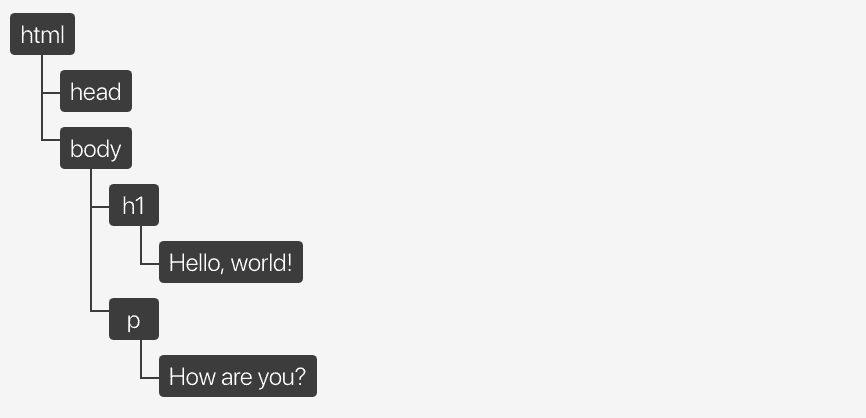
La structure d'objet du DOM est représentée par ce qu'on appelle une "arborescence de noeuds" (node tree). On l'appelle ainsi parce qu'il peut être considéré comme un arbre qui se ramifie en plusieurs branches enfants, chacune pouvant avoir des feuilles. Le premier parent est l'élément racine <html>, les "branches" enfants sont les éléments imbriqués et les "feuilles" sont le contenu des éléments.
Prenons par exemple ce document HTML :
<!doctype html>
<html lang="en">
<head>
<title>My first web page</title>
</head>
<body>
<h1>Hello, world!</h1>
<p>How are you?</p>
</body>
</html>Ce document peut être représenté comme une arborescence de noeuds :

Ce que n'est pas le DOM
De l'exemple ci-dessus on pourrait conclure que le DOM est un mapping exact du document source HTML ou de ce que vous voyez dans votre DevTools. Cependant, il y a des différences. Pour bien comprendre ce qu'est le DOM, nous devons d'abord comprendre ce qu'il n'est pas.
Le DOM n'est pas votre HTML source
Bien que créé à partir du document source HTML, le DOM n'en est pas toujours l'exact reflet. Il peut en différer dans deux cas :
1. Lorsque le HTML n'est pas valide
Le DOM est une interface pour les documents HTML valides. Pendant le processus de création du DOM, le navigateur peut être amené à corriger des informations invalides.
Prenons ce document HTML par exemple :
<!doctype html>
<html>
Hello, world!
</html>Il manque les éléments <head> et <body> à ce document, alors qu'ils sont requis dans un HTML valide. Si nous inspectons l'arborescence créée, nous pouvons constater que l'erreur a été corrigée :

2. Lorsque le DOM est modifié par JavaScript
En plus d'être une interface permettant de visualiser le contenu d'un document HTML, le DOM peut être modifié, ce qui en fait une ressource vivante.
Nous pouvons par exemple créer des noeuds supplémentaires via JavaScript.
var newParagraph = document.createElement("p");
var paragraphContent = document.createTextNode("I'm new!");
newParagraph.appendChild(paragraphContent);
document.body.appendChild(newParagraph);Le DOM sera mis à jour, mais bien entendu notre document source HTML restera inchangé.
Le DOM n'est pas ce que vous voyez dans le navigateur
Ce que vous voyez dans le viewport de votre navigateur c'est l'arbre de rendu qui, nous l'avons vu, est un mélange de DOM et de CSSOM. Ce qui distingue le DOM de l'arbre de rendu c'est que ce dernier ne comprend que ce qui sera "peint" à l'écran. De ce fait, il exclut les éléments visuellement cachés, par exemple ceux stylés display: none.
<!doctype html>
<html lang="en">
<head></head>
<body>
<h1>Hello, world!</h1>
<p style="display: none;">How are you?</p>
</body>
</html>Le DOM comprendra l'élément<p>:
Cependant l'arbre de rendu — et donc ce qui est visible dans le viewport — ne comprendra pas cet élément.

Le DOM n'est pas ce que vous voyez dans DevTools
Cette différence ne tient pas à grand chose car l'inspecteur d'éléments DevTools offre la meilleure approximation du DOM disponible dans le navigateur. Toutefois DevTools inclut des informations qui ne sont pas dans le DOM.
Le meilleur exemple en est les pseudo-éléments CSS créées via les sélecteurs ::before et ::after. Ils font partie du CSSOM et de l'arbre de rendu mais techniquement ils n'appartiennent pas au DOM puisque celui-ci est construit à partir du seul document source HTML, qui ne comprend pas les styles appliqués aux éléments.
Bien que ne faisant pas partie du DOM, les pseudo-éléments apparaissent dans notre inspecteur DevTools :
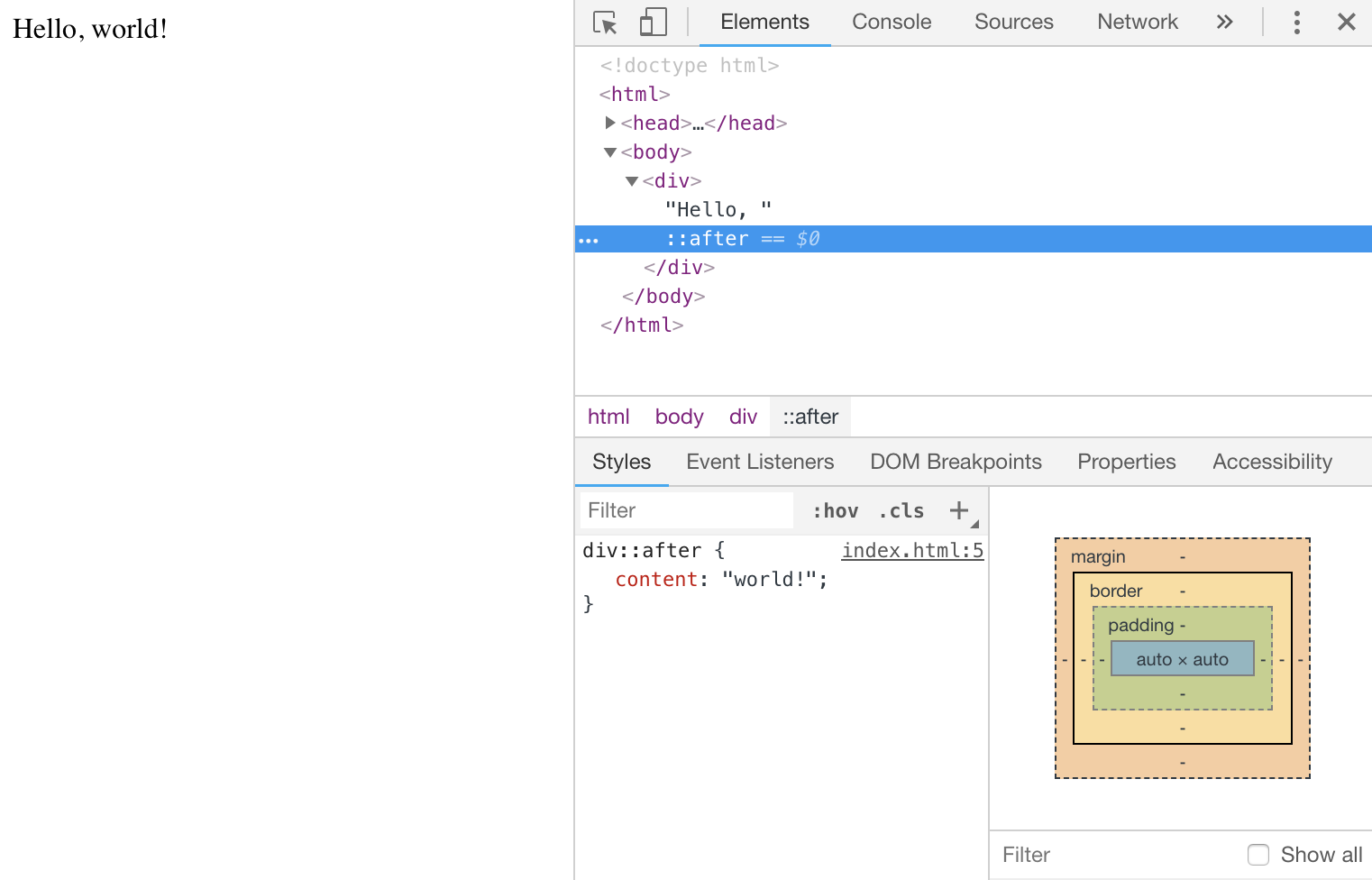
C'est la raison pour laquelle les pseudo-éléments ne peuvent pas être ciblés par JavaScript, parce qu'ils ne font pas partie du DOM !
On récapitule
Le DOM est une interface vers un document HTML. Il est utilisé par les navigateurs dans une première étape pour déterminer ce qui peut être rendu à l'écran, et par JavaScript pour modifier le contenu, la structure ou le style de la page.
Bien que similaire à d'autres formes de documents source HTML, il en diffère en plusieurs points :
- son HTML est toujours valide
- c'est un modèle vivant qui peut être modifié par JavaScript
- il ne comprend pas de pseudo-éléments (p.ex.
::after) - il ne comprend pas d'élémens cachés (p.ex. via
display: none)