Introduction à RDFa, 1ère partie
RDFa connaît sa petite heure de gloire : Google utilise RDFa et les microformats pour indexer les sites web, et utilise les données analysées pour enrichir la présentation des résultats de recherche par des "rich snippets" (extraits enrichis). Yahoo! utilise RDFa depuis plus longtemps encore (1). Avec ces deux moteurs de recherche géants sur la même trajectoire, un web nouveau est plus près que jamais.
Le web est conçu pour être consommé par des humains, et la plupart des informations riches et utiles que contiennent nos sites sont inaccessibles aux machines. Les humains peuvent s'adapter à toutes sortes de variations dans la mise en page, l'orthographe, les majuscules, les couleurs, la position du texte etc, et absorber la signification de la page dans toutes ses subtilités. Les machines, elles, ont besoin d'un peu d'aide.
Un nouveau web — un web sémantique — serait fait d'informations balisées d'une manière telle qu'un programme puisse facilement le comprendre. Avant de voir comment nous pourrions y parvenir, voyons ce que nous serions capables de faire avec lui.
Recherche améliorée
Ajouter à une page des données accessibles aux machines améliore notre capacité à trouver la bonne information. Imaginons un titre de journal annonçant "aujourd'hui le premier ministre s'est envolé pour l'Australie", en référence au premier ministre britannique, Gordon Brown. L'article ne nomme pas le premier ministre mais il est assez certain que cette information apparaîtra lorsque quelqu'un fera une recherche sur le nom de Gordon Brown.
Si cette information date de 1940 toutefois, nous ne voudrions pas qu'elle apparaisse dans une recherche sur Gordon Brown, par contre nous voudrions qu'elle apparaisse dans une recherche sur Winston Churchill.
Pour y parvenir, notre moteur de recherche doit associer un ensemble de données à un autre, il lui faut connaître les dates auxquelles les premiers ministres britanniques ont exercé leurs fonctions, puis les croiser avec la date de publication de l'article. Cela ne serait pas complètement impossible, mais quid si l'article en question est une fiction ou s'il concerne en réalité le premier ministre australien ? Les dates ne suffisent plus.
Les algorithmes d'indexation qui tentent de déduire un contexte à partir du texte s'amélioreront avec le temps, mais un balisage supplémentaire qui rend l'information non ambigüe ne peut qu'aider à la précision de la recherche.
De meilleures interfaces utilisateurs
Yahoo! et Google ont tous les deux commencé à utiliser RDFa pour améliorer l'expérience utilisateur en mettant en valeur la façon dont apparaissent les résultats de recherche. Voici l'approche de Google :

...et voici celle de Yahoo! :
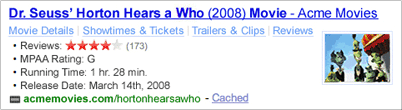
Il y a aussi un avantage commercial à avoir une meilleure "compréhension" des pages indexées : des publicités plus pertinentes, plus focalisées peuvent être placées à côté des résultats de recherche.
Maintenant que nous savons pourquoi nous pourrions avoir intérêt à insérer des donner plus accessibles aux machines, voyons comment nous pourrions y parvenir.
Les métadonnées dans HTML
Vous connaissez déjà les métadonnées basiques de HTML. Les plus utilisées sont les éléments meta et link , et vous savez peut-être que l'attribut @rel utilisé dans link peut aussi l'être dans a . (NB : j'utiliserai le terme "HTML" pour désigner "la famille de langages HTML", puisque ce que je décris s'applique de la même façon à HTML et XHTML).
Nous allons dans un premier temps nous pencher sur ces caractéristiques existantes, parce qu'elles nous fournissent le fondement conceptuel sur lequel RDFa a été bâti.
L'utilisation de meta et link en HTML
Les éléments meta et link sont situés dans la partie <head> d'un document HTML, ils permettent de fournir des informations relatives à ce document. Par exemple, je pourrais vouloir indiquer qu'il a été créé le 9 mai 2009, que j'en suis l'auteur et que je donne l'autorisation à tous d'utiliser cet article :
<html>
<head>
<title>RDFa: Tout le monde peut avoir une API</title>
<meta name="author" content="Mark Birbeck" />
<meta name="created" content="2009-05-09" />
<link
rel="license"
href="http://creativecommons.org/licenses/by-sa/3.0/"
/>
</head>
</html>Avec cet exemple, on voit comment HTML distingue clairement les métadonnées du document dans un espace distinct du texte principal. HTML utilise l'élément head pour les métadonnées et l'élément body pour le contenu de la page.
HTML nous permet aussi de rendre plus floues les frontières : nous pouvons placer l'attribut @rel dans un lien cliquable, tout en gardant la signification qu'il a dans link.
Utilisation de @rel
Imaginons que je veuille permettre aux visiteurs de mon site de voir ma license Creative Commons. En l'état actuel des choses, l'information dont je parle est cachée des lecteurs parce qu'elle est contenue dans le head. C'est facilement résolu en ajoutant une ancre dans le body :
<a href="http://creativecommons.org/licenses/by-sa/3.0/"
>CC Attribution-ShareAlike</a
>Voilà qui nous permet d'atteindre nos objectifs : d'abord, nous avons des métadonnées lisibles par les machines dans le head qui décrivent la relation entre le document et la licence :
<link
rel="license"
href="http://creativecommons.org/licenses/by-sa/3.0/"
/>...ensuite, nous avons un lien dans le body qui permet aux humains de cliquer et de lire la licence :
<a href="http://creativecommons.org/licenses/by-sa/3.0/"
>CC Attribution-ShareAlike</a
>Mais HTML nous permet également d'utiliser l'attribut @rel de link sur une ancre. En d'autres termes, il permet à des métadonnées qui devraient normalement figurer dans head d'apparaître dans le body.
Avec cette technique incroyablement puissante, nous pouvons exprimer à la fois les métadonnées pour les machines et le lien cliquable pour les humains, en une formule unique et pratique ,:
<a rel="license" href="http://creativecommons.org/licenses/by-sa/3.0/"
>CC Attribution-ShareAlike</a
>Cette méthode simple d'enrichissement du balisage inline n'est pas souvent utilisée dans les pages web, mais elle est au coeur de RDFa. Cela nous conduit au premier principe de RDFa :
Règle n°1 :
Les éléments link et a impliquent une relation entre le document courant et un autre document; l'attribut @rel nous permet de fournir une valeur qui décrira mieux cette relation.
Cependant, soyons clairs : l'utilisation de @rel avec a consiste à tirer parti d'une caractéristique déjà existante de HTML, sur laquelle RDFa ne fait qu'attirer l'attention.
Appliquer des licences distinctes
L'exemple précédent fournit une information à propos de la page web dans laquelle elle est incluse. Mais que se passe-t-il si la page contient plusieurs objets qui ont chacun une licence différente ? Les exemples de scénario abondent, tels que les pages de résultats de recherche de Flickr, Youtube ou SlideShare.
RDFa utilise l'idée simple qui sous-tend @rel — l'idée qu'il exprime la relation entre deux choses — en appliquant cet attribut à l'attribut @src de l'élément img.
Imaginons par exemple une page de résultats de recherche sur Flickr :
<img src="http://la-cascade.ghost.io/image1.png" />
<img src="http://la-cascade.ghost.io/image2.png" />Supposons que les deux pages ont une licence Creative Commons, la première image en Attribution-ShareAlike, la seconde en Attribution-Noncommercial-No Derivative works.
Quelles balises utiliser ?
Si vous avez deviné qu'il suffit de placer l'attribut @rel dans la balise img, bravo. Pour exprimer deux licences différentes, une pour chaque image, il suffit d'écrire :
<img
src="http://la-cascade.ghost.io/image1.png"
rel="license"
href="http://creativecommons.org/licenses/by-sa/3.0/"
/>
<img
src="http://la-cascade.ghost.io/image2.png"
rel="license"
href="http://creativecommons.org/licenses/by-nc-nd/3.0/"
/>Ici, vous voyez le principe de base en action — construire à partir des métadonnées déjà fournies par HTML. Partir de la structure de description inhérente au concept HTML permet de mieux s'orienter lorsqu'on utilise RDFa.
Règle n°2 :
Les attributs @rel et @href ne sont plus confinés aux éléments a et link, ils peuvent aussi être utilisés avec img pour indiquer une relation entre une image et autre chose.
Ajouter des propriétés à body
Dans notre illustration HTML, nous avons vu que nous pouvons aussi ajouter des propriétés textuelles au sujet du document :
<meta name="author" content="Mark Birbeck" />
<meta name="created" content="2009-05-01" />Cela nous dit qui a créé le document, et quand, mais on ne peut l'utiliser que dans la partie head du document. RDFa reprend cette technique et l'améliore en rendant son utilisation possible dans body. @content n'est plus confiné à la balise meta, il peut apparaître dans n'importe quel élément.
Règle n°3 :
Dans le HTML habituel, les propriétés sont fixées dans la partie head du document en utilisant @contentavec meta. Dans les documents HTML comportant RDFa, @content peut être utilisé pour fixer les propriétés de n'importe quel élément.
Il y a un petit changement par rapport à la façon dont @content est utilisé dans head, car comme l'attribut @name est déjà présent dans HTML, cela pourrait créer une certaine confusion. RDFa fournit un autre attribut appelé @property pour remplir ce rôle.
Règle n°4 :
Bien qu'HTML utilise la propriété @name pour fixer le nom d'une propriété dans meta, il ne peut pas être utilisé dans d'autres éléments, RDFa fournit à la place un nouvel attribut appelé @property.
Supposons que la date de publication de notre document et le nom de son auteur figurent dans la partie head de notre document et que ces mêmes informations figurent sous une forme lisible dans le corps du document :
<html>
<head>
<title>RDFa: Tout le monde peut avoir une API</title>
<meta name="author" content="Mark Birbeck" />
<meta name="created" content="2009-05-09" />
</head>
<body>
<h1>RDFa: Tout le monde peut avoir une API</h1>
Author: <em>Mark Birbeck</em> Created: <em>May 9th, 2009</em>
</body>
</html>Avec RDFa, nous pouvons fondre ces deux ensembles d'informations, les métadonnées, lisibles par les machines, étant localisées au même endroit que le texte lisible par les humains :
<html>
<head>
<title>RDFa: Tout le monde peut avoir une API</title>
</head>
<body>
<h1>RDFa: Now everyone can have an API</h1>
Author:
<em property="author" content="Mark Birbeck">Mark Birbeck</em>
Published:
<em property="created" content="2009-05-14">May 14th, 2009</em>
</body>
</html>Nous allons voir dans un instant comment nous pouvons améliorer encore cet exemple. Pour l'instant, il nous suffit de constater que la localisation de ces métadonnées dans le body ou dans le head est équivalente.
Utiliser des vocabulaires
Nous devons faire un petit détour ici. Nous pouvons nous permettre d'utiliser @name="author" dans le head car même si la propriété "author" (auteur) n'est définie dans aucune spécification, on a fini par l'intégrer. Mais RDFa permet — et requiert — une plus grande précision. Quand nous utilisons un terme comme "author" ou "created", nous devons indiquer d'où ce terme provient. Sinon, il n'y a pas moyen de savoir si vous donnez à "author" le même sens que quelqu'un d'autre.
Cela peut paraître inutile. Après tout, comment pourrait-il y avoir confusion sur un terme aussi simple ? Mais imaginons que le terme soit "country" sur un site de vacance, est-ce que ce terme désigne le pays ou bien la campagne ? (2) Beaucoup de mots prêtent à confusion et si vous y ajoutez un contexte multilingue vous verrez que si nous voulons avancer avec nos métadonnées nous devons être précis. Cela impose d'indiquer la provenance des termes que nous utilisons.
En RDFa, on indique que l'on se réfère à un vocabulaire, dont on spécifie l'adresse ainsi :
xmlns:dc="http://purl.org/dc/terms/"Si vous avez des notions d'XML, vous reconnaîtrez la syntaxe d'une déclaration d'espace de nom XML (3).
Cet exemple nous donne un accès aux listes de termes du vocabulaire Dublin Core, grâce au préfixe "dc". Dublin Core contient de nombreux termes (4), nous utiliserons ici "creator" et "created", avec le préfixe :
- dc:creator
- dc:created
Maintenant les choses sont claires, "dc:creator" n'est pas la même chose que "xyz:creator".
Pour que cela fonctionne, il faut déclarer quelque part en haut du document que l'on pointe vers ce vocabulaire. Dans notre exemple, cela pourrait se faire dans l'élément body ou html. L'exemple complet devient :
<html xmlns:dc="http://purl.org/dc/terms/">
<head>
<title>RDFa: Tout le monde peut avoir une API</title>
</head>
<body>
<h1>RDFa: Tout le monde peut avoir une API</h1>
Author:
<em property="dc:creator" content="Mark Birbeck">Mark Birbeck</em>
Published:
<em property="dc:created" content="2009-05-09">May 9th, 2009</em>
</body>
</html>Les vocabulaires sont nombreux et vous pouvez même inventer le vôtre pour votre société, organisation, groupe d'intérêts. S'il n'existe pas d'organisation centralisée, il existe en revanche de bonnes pratiques. Le pouvoir impose des responsabilités, alors renseignez-vous bien avant de vous lancer dans la rédaction d'un nouveau vocabulaire.
Avant de revenir à notre exemple, je voudrais ajouter encore une chose à propos des vocabulaires. Vous vous demandez certainement pourquoi @rel="license" n'a pas eu le même traitement que @rel="author" et requiert un préfixe. La réponse est que HTML vient déjà avec des valeurs pré-construites à utiliser avec @rel (comme "next" et "prev") et RDFa en ajoute quelques autres. L'une d'elles est "license". Mais une fois que vous sortez de cette liste de valeurs — par exemple en utilisant un terme du vocabulaire Dublin Core comme "replaces" ou un terme de FOAF comme "knows" — alors vous devez utiliser un préfixe comme nous l'avons fait pour @property.
Par exemple, admettons que notre article remplace un autre document, une relation que nous pouvons exprimer avec l'expression Dublin Core "replaces" :
<html xmlns:dc="http://purl.org/dc/terms/">
<head>
<title>RDFa: Tout le monde peut avoir une API</title>
</head>
<body>
<h1>RDFa: Tout le monde peut avoir une API</h1>
Author:
<em property="dc:creator" content="Mark Birbeck">Mark Birbeck</em>
Created:
<em property="dc:created" content="2009-05-09">May 9th, 2009</em>
License:
<a
rel="license"
href="http://creativecommons.org/licenses/by-sa/3.0/"
>CC Attribution-ShareAlike</a
>
Previous version:
<a
rel="dc:replaces"
href="http://la-cascade.ghost.io/rdfa.0.8.html"
>version 0.8</a
>
</body>
</html>Maintenant que nous comprenons les vocabulaires, revenons à notre exemple principal.
Valeur texte d'une propriété
Dans l'exemple précédent, la duplication du texte "Mark Birbeck", dans l'attribut @content et dans le texte est problématique. Nous pouvons supprimer @content si le texte contient la valeur de la métadonnée :
Author: <em property="dc:creator">Mark Birbeck</em>Règle n°5 :
S'il n'y a pas d'attribut @content, la valeur de la propriété sera celle du texte inline.
Cette façon de faire peut être considérée comme la pratique par défaut, l'insertion d'une valeur @content pouvant être une façon d'outrepasser la valeur textuelle si celle-ci ne dit pas exactement ce que vous souhaitez. Elle donne plus de liberté d'action aux auteurs quant au texte qu'ils veulent donner aux lecteurs, tout en étant précis dans les métadonnées. La date de publication illustre bien ce cas. Toutes les données qui suivent ont la même signification, dans des présentations très différentes :
<span property="dc:created" content="2009-05-14">May 14th, 2009</span>
<span property="dc:created" content="2009-05-14">May 14th</span>
<span property="dc:created" content="2009-05-14">14 Mai</span>
<span property="dc:created" content="2009-05-14">14/05/09</span>
<span property="dc:created" content="2009-05-14">demain</span>
<span property="dc:created" content="2009-05-14">hier</span>
<span property="dc:created" content="2009-05-14">14 Mai, 2009</span>
<span property="dc:created" content="2009-05-14"
>14 maggio, 2009</span
>Règle n°6 :
Si l'attribut @content est présent, c'est son contenu qui établit la valeur de la propriété, et non pas le texte inline de l'élément.
Ajouter des propriétés à une image
Nous pouvons également ajouter des propriétés à une image. Par exemple, pour indiquer sa date de création, nous pouvons écrire :
<img
src="http://la-cascade.io/image1.png"
property="dc:created"
content="2009-03-22"
/>
<img
src="http://la-cascade.io/image2.png"
property="dc:created"
content="2009-05-01"
/>Règle n°7 :
Le HTML ordinaire permet d'établir des propriétés de la page, RDFa permet en outre d'établir des propriétés pour les URL d'images.
RDFa permet également d'exprimer une propriété et une relation pour la même image :
<img
src="http://la-cascade.ghost.io/image1.png"
rel="license"
href="http://creativecommons.org/licenses/by-sa/3.0/"
property="dc:created"
content="2009-05-01"
/>Ajouter des métadonnées à n'importe quel objet
En suivant l'évolution d'un HTML basique vers RDFa, nous avons fait trois pas importants :
- Nous avons noté que n'importe quelle métadonnée exprimée dans le
headd'un document peut être utilisée dans sonbody— moyennant le changement de l'attribut@nameen@property. - Nous avons vu comment RDFa permet d'utiliser des vocabulaires clairement définis.
- Nous avons appris que RDFa permet d'exprimer des propriétés et des relations à propos d'images ou à propos du document courant.
Puisque nous pouvons ajouter des propriétés et des relations à des images, pourquoi pas généraliser ? Si je peux indiquer la licence de ce document et la licence des images, pourquoi pas indiquer les licences de tout ce à quoi je me réfère dans ma page web ?
Par exemple, admettons que j'aie quelques liens vers des présentations SlideShare sur RDFa :
<a href='http://www.slideshare.net/fabien_' gandon/rdfa-in-a-nutshell-v1">RDFa in a nutshell</a>
<a href='http://www.slideshare.net/mark.birbeck/the-5-minute-guide-to-rdfain-only-6-minutes-40-seconds' >The 5-minute guide to RDFa… in only 6 minutes and 40 seconds</a>Si vous regardez ces pages sur SlideShare, vous verrez que les informations relatives à la licence sont clairement affichées. Mais quid si nous voulions ajouter cette information au document en cours, de façon à ce qu'un navigateur intelligent puisse en faire quelque chose ? (La page pourrait être, par exemple, un ensemble de résultats de recherche, nous pourrions vouloir afficher les licences de façon à aider l'internaute à choisir les documents).
Nous pourrions penser qu'il suffit d'utiliser @rel="license" sur ces ancres, comme d'habitude, mais rappelez-vous que cela implique que le document courant ait une licence identifiée par l'item dans l'attribut @href. Dans le cas présent, l'autre document est une page SlideShare, pas une licence.
Pour rendre possible l'insertion d'informations additionnelles à propos de n'importe quelle ressource, RDFa ajoute un nouvel attribut appelé @about. Il est calqué sur le modèle de l'attribut @src dans les images, c'est à dire qu'il peut contenir des informations @rel et @property, mais il peut être utilisé sur n'importe quel élément HTML. Voici comment utiliser @about pour nous aider à ajouter des informations relatives aux licences de nos slides. Notre premier lien :
<a
href="http://www.slideshare.net/fabien_gandon/rdfa-in-a-nutshell-v1"
>RDFa in a nutshell</a
>...est enrichi ainsi :
<a
about="http://www.slideshare.net/fabien_gandon/rdfa-in-a-nutshell-v1"
rel="license"
href="http://creativecommons.org/licenses/by/2.5/"
>CC BY</a
>.Notez bien au passage que du point de vue du processeur RDFa cette information peut figurer n'importe où dans le document, elle n'a pas besoin d'apparaître à côté du lien. Pour les humains bien sûr, c'est plus logique.
La deuxième présentation :
<a
href="http://www.slideshare.net/mark.birbeck/the-5-minute-guide-to-rdfain-only-6-minutes-40-seconds"
>The 5-minute guide to RDFa…in only 6 minutes and 40 seconds</a
>...reçoit sa licence en ajoutant le balisage suivant :
<a
about="http://www.slideshare.net/mark.birbeck /the-5-minute-guide-to-rdfain-only-6-minutes-40-seconds"
rel="license"
href="http://creativecommons.org/licenses/by-sa/2.5/"
>CC BY SA</a
>.Là encore, ce balisage pourrait apparaître n'importe où.
Notez que la référence à chaque licence reste un lien cliquable, donc du point de vue de l'utilisateur rien ne change lorsqu'on ajoute @about à l'ancre. Mais du point de vue des métadonnées, chaque licence est maintenant appliquée à un document externe qui contient une présentation, plutôt qu'au document courant.
Bien sûr, dans un exemple réel les liens cliquables contiendraient probablement les icônes Creative Commons :
<a
about="http://www.slideshare.net/mark.birbeck/the-5-minute-guide-to-rdfain-only-6-minutes-40-seconds"
rel="license"
href="http://creativecommons.org/licenses/by-sa/2.5/"
><img src="http://i.creativecommons.org/l/by-sa/2.5/80x15.png"
/></a>Vous l'avez sans doute déjà compris, nous pouvons aussi ajouter @property et @content aux ressources référencées par @about. Par exemple si nous voulions ajouter des informations sur le créateur de la présentation, nous pourrions écrire :
<a
about="http://www.slideshare.net/fabien_gandon/rdfa-in-a-nutshell-v1"
rel="license"
href="http://creativecommons.org/licenses/by/2.5/"
property="dc:creator"
content="Fabien Gandon"
><img src="http://i.creativecommons.org/l/by/2.5/80x15.png"
/></a>Règle n°8 :
Propriétés et relations peuvent être spécifiées pour n'importe quelle ressource en utilisant l'attribut @about de RDFa.
Utiliser @about
Quelle technique utiliser pour attribuer plusieurs propriétés avec @about ? Jusqu'ici, nos exemples ne comportaient qu'une seule propriété et une seule relation pour chaque objet, parce que c'est la limite imposée par la structure d'HTML : dans un élément, chaque attribut doit avoir un nom unique, il n'est donc pas possible de spécifier des valeurs ou des relations multiples.
La réponse est très simple. En RDFa, l'attribut @about utilisé dans un élément établit le contexte par rapport auquel se situe les éléments "enfants". Rappelons-nous notre dernier exemple :
<a
about="http://www.slideshare.net/fabien_gandon/rdfa-in-a-nutshell-v1"
rel="license"
href="http://creativecommons.org/licenses/by/2.5/"
property="dc:creator"
content="Fabien Gandon"
><img src="http://i.creativecommons.org/l/by/2.5/80x15.png"
/></a>Ce balisage dit deux choses, d'abord que "la présentation SlideShare visionnable à l'URL spécifiée comporte une licence CC BY", ensuite que "la présentation SlideShare visionnable à l'URL spécifiée a été créée par Fabien Gandon".
Pour rendre plus tangible le probème que nous cherchons à résoudre, imaginons que nous voulions aussi ajouter la date à laquelle la présentation a été publiée — sachant que nous ne sommes pas autorisés à ajouter un deuxième attribut @property à notre ancre.
La façon la plus simple d'y parvenir est de créer un élément qui contienne le contexte dans lequel nous voulons qu'opèrent tous nos RDFa, dans ce cas c'est l'adresse de la présentation :
<div
about="http://www.slideshare.net/fabien_gandon/rdfa-in-a-nutshell-v1"
>
...
</div>Une fois que nous avons ceci, nous pouvons ajouter toutes les propriétés que nous voulons :
<div
about="http://www.slideshare.net/fabien_gandon/rdfa-in-a-nutshell-v1"
>
<h1>RDFa in a Nutshell</h1>
<ul>
<li>Author:<em property="dc:creator">Fabien Gandon</em></li>
<li>
Created:<em property="dc:created" content="2007-01-01"
>Jan 1st, 2007</em
>
</li>
<li>
License:
<a
rel="license"
href="http://creativecommons.org/licenses/by/2.5/"
><img src="http://i.creativecommons.org/l/by/2.5/80x15.png"
/></a>
</li>
</ul>
</div>Si ce layout vous semble familier, c'est parce que c'est exactement celui que nous avons vu lorsque nous avons ajouté des propriétés au "document courant" :
<html xmlns:dc="http://purl.org/dc/terms/">
<head>
<title>RDFa: Tout le monde peut avoir une API</title>
</head>
<body>
<h1>RDFa: Tout le monde peut avoir une API</h1>
<ul>
<li>Author: <em property="dc:creator">Mark Birbeck</em></li>
<li>
Created:
<em property="dc:created" content="2009-05-09"
>May 9th, 2009</em
>
</li>
<li>
License:
<a
rel="license"
href="http://creativecommons.org/licenses/by-sa/3.0/"
>CCAttribution-ShareAlike</a
>
</li>
<li>
Version précédente:
<a
rel="dc:replaces"
href="http://la-cascade.ghost.io/rdfa.0.8.html"
>version 0.8</a
>
</li>
</ul>
</body>
</html>La seule différence est que le contexte de toutes les propriétés et relations que nous avons ajoutées est défini par @about, alors que dans le premier exemple le contexte était simplement le document lui-même.
Règle n°9 :
La propriété @about établit le contexte de toutes les propriétés et relations contenues. S'il n'y a pas de valeur définie avec @about, toutes les propriétés et relations feront référence au document courant.
Cette technique est sans doute ce qui fait la différence essentielle entre RDFa et les autres méthodes de structuration de données dans HTML, telles que les Microformats et eRDF.
Notes du traducteur :
1 - Cet article date de 2009. Google, Yahoo! et Bing utilisent aujourd'hui les microdonnées (microdata) pour enrichir le contenu, dans le cadre d'un schéma commun, schema.org.
Voici ce que dit Google à son propos :
À l'origine, trois formats de balisage des données structurées sont compatibles : les microdonnées, les microformats et RDFa. Pour schema.org, nous avons décidé de nous concentrer sur un seul format, afin d'éviter que les webmasters ne soient obligés de faire un choix difficile. De plus, un format unique permet d'améliorer la cohérence entre les moteurs de recherche qui se basent sur ces données. Chacun des formats présente des avantages particuliers, mais nous avons trouvé que les microdonnées offraient un juste équilibre entre la capacité d'extension de RDFa et la simplicité des microformats. C'est pour cette raison que nous avons choisi ce format.
Comme le rappelle Google, RDFa est un langage plus riche et extensible que les microdonnées, et il est compatible avec les outils de mise en valeur du contenu (rich snippets et autres) des moteurs de recherche. Vous pouvez combiner RDFa et les microdonnées dans votre HTML pour avoir un contenu parfaitement sémantique ! ↩
2 - En anglais, le terme country peut désigner le pays, ou la campagne par opposition à la ville. ↩
3 - xmlns: espace de nom (Name Space = ns) XML, et dc = Dublin Core ↩
4 - Dublin Core lui-même en contient très peu (comme son nom l'indique), il s'agit des 15 termes considérés comme essentiels. Dublin Core 'qualified' en ajoute de plus spécifiques. ↩